Introduction: Why AI-Driven Workflows Are Important in SRE
Site Reliability Engineering (SRE) teams are operating at scale: distributed services, polyglot stacks, and multi-vendor observability produce an increasing surface area for failures and more signals to reason about. That complexity manifests as operational friction; many teams report that running and understanding cloud-native stacks is becoming increasingly challenging year over year.
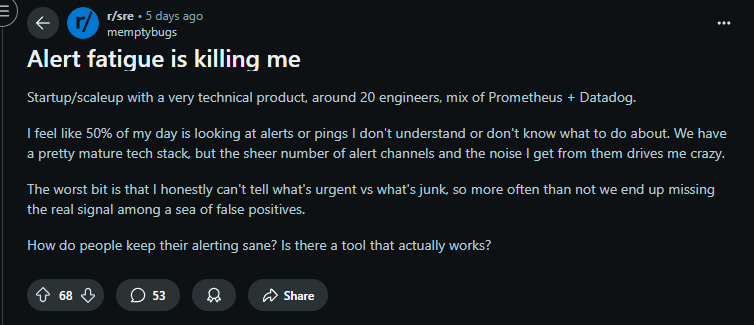
Alert volume and non-ticketed incidents are concrete symptoms. In a recent industry snapshot, 71% of SREs reported responding to “dozens or hundreds” of non-ticketed incidents per month, a pattern that drives context switching and slows down meaningful reliability work. Practitioners in the community echo this; forums like r/sre are full of threads describing alert fatigue, noisy alerts that aren’t actionable, and calls to simply delete alerts that provide no value.
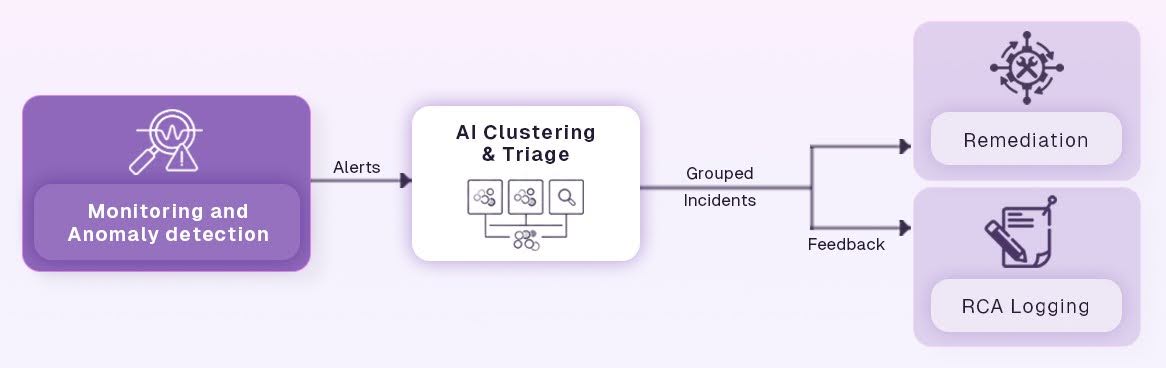
This is precisely where AI SRE, the practice of embedding intelligence into reliability workflows, becomes useful. Practical AI capabilities, such as anomaly detection, correlation across metrics/logs/traces, and automated recommendations, reduce noise and speed up triage when integrated into workflow steps rather than bolted on as standalone features. Platforms and tooling are increasingly shipping these capabilities as part of observability and AIOps stacks, enabling teams to detect problems earlier and prioritize real user impact.
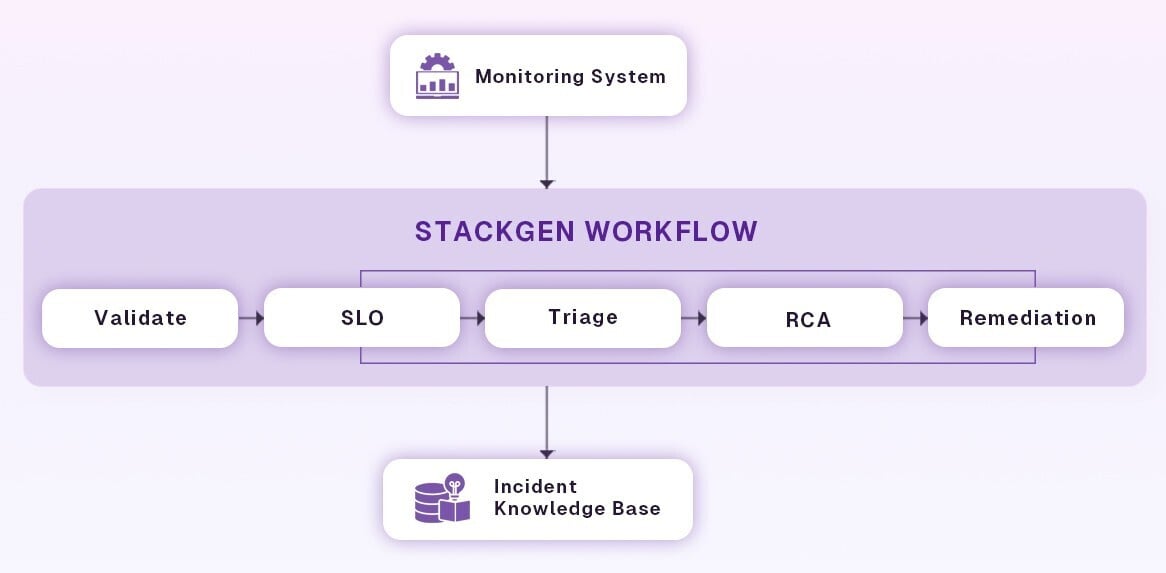
Workflows matter because they are the mechanism that turns insight into action. An AI signal that only creates another alert leaves engineers where they started; an AI signal that becomes a reproducible, auditable workflow step (triage, then escalation, then RCA capture, and then finally safe remediation) converts time-sink noise into repeatable reliability practice. The rest of this guide shows how to design those AI-driven workflow steps so teams can work faster, be less interrupted, and feel more confident in production changes.