

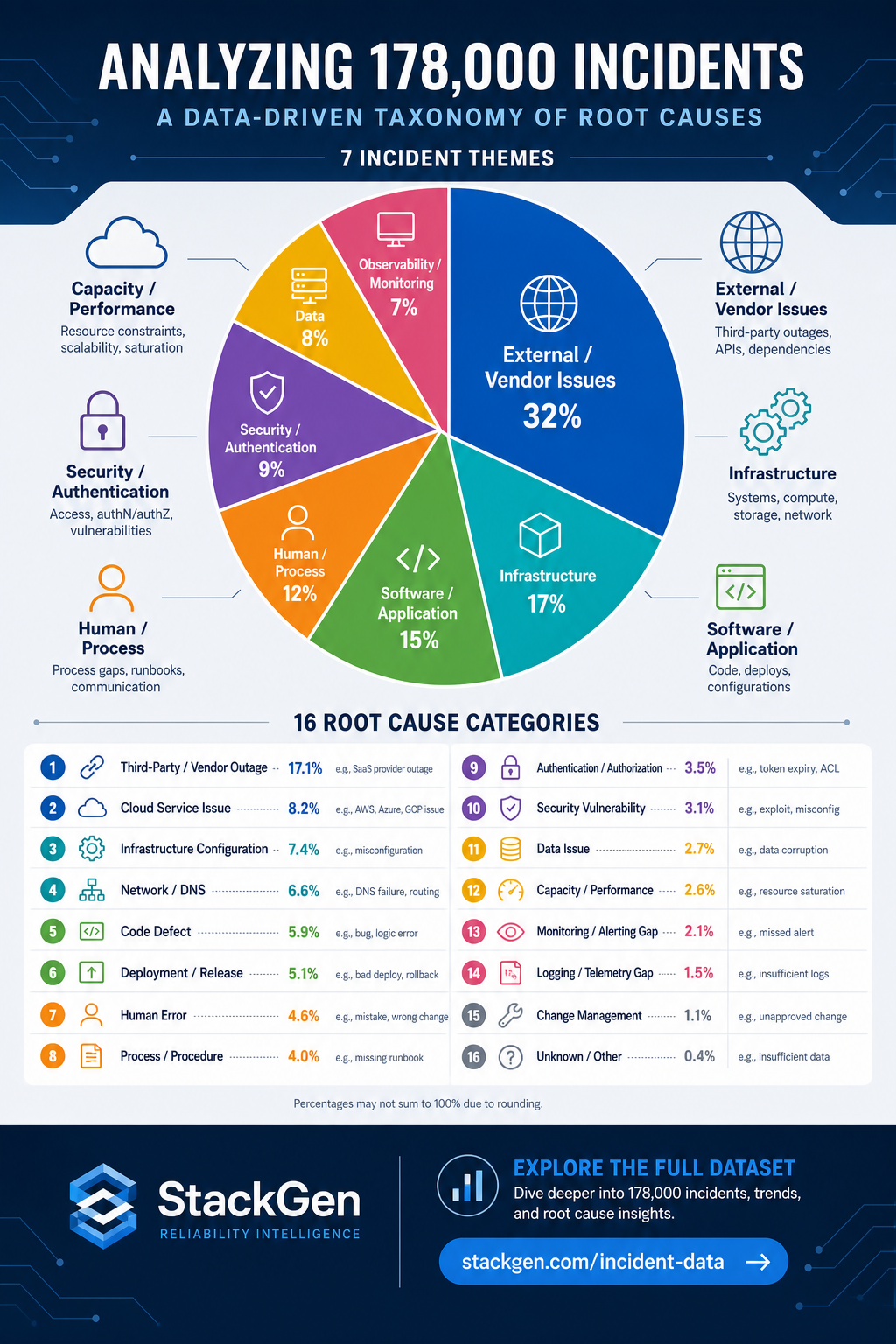
Root cause analysis is SRE's core ritual. But the answers are inconsistent because there's no shared vocabulary for what kind of cause it was. We built one.
Across 178,000+ status page incidents and 1,037 engineering post-mortems, we classified every disclosed cause against a structured root cause taxonomy: 16 categories, 7 themes, grounded in what operators actually say happened.
For the full dataset, see the StackGen State of Reliability 2026 report.
Two Cuts on Every Incident
Failure mode = how it broke (the pattern). Root cause = why it broke (the technical trigger). A deploy regression (FM-09) can be triggered by a code defect (RC-01) or a third-party dependency change (RC-08). The two taxonomies compose.
The 7 Themes, 16 Root Causes
Theme 1: Change (26%)
RC-01 Code Defect (3,609): logic regressions, dependency incompatibilities, performance regressions. RC-02 Config Change (1,551): the subtler sibling. The Cloudflare November 2025 outage traces to RC-02 \u2014 a single ClickHouse permissions change, global impact.
Theme 2: Capacity and Quota (9%)
RC-04 Capacity Exhaustion (1,690): demand outruns supply. RC-05 Quota / Rate Limit (233): the externally-imposed variant \u2014 API rate limits silently degrading downstream services.
Theme 3: Infrastructure (13%)
RC-06 Network / DNS (1,804): DNS record edits, TLS cert expirations, routing misconfigurations. RC-11 Hardware Failure (848): historically rare, but growing as AI training clusters surface hardware failures. Linode disclosed RTX 4000 Ada GPU errors across multiple regions in March 2026; Baseten disclosed A100 node failures multiple times in 2025.
Theme 4: Auth and Security (10%)
RC-07 Auth (1,778): expired certificates, IAM policy tightenings, OAuth scope changes, MFA outages. When Okta has a federation issue, every operator trusting Okta as their identity layer is affected.
Theme 5: External / Vendor (21%) \u2014 the largest
RC-08 Third-Party / Vendor (4,271): 1 in 5 incidents traces to a vendor you don't control. AWS us-east-1 Oct 2025 generated 137 downstream incidents in 24 hours \u2014 all RC-08. The CrowdStrike Falcon update July 2024 cascaded across banking, airlines, and healthcare. Azure Oct 2024 hit dozens of European operators.
| Upstream | Examples |
| Cloud | AWS, GCP, Azure |
| CDN | Cloudflare, Fastly, Akamai |
| Identity | Okta, Auth0, CrowdStrike |
| AI Provider | OpenAI, Anthropic, Deepgram |
| Dev-Tooling | GitHub, Docker Hub, npm |
The most common remediation: wait for upstream fix (13.6% of post-mortem corpus). For Dependency-Driven teams: 74% of cases.
Theme 6: Data Pipeline (18%)
RC-09 Data Processing / Pipeline (3,686): queue backlogs, replication lag crossing business thresholds, ETL silent failures. Datadog June 2025 data delays (2.1 days) and OpenAI Compliance API delays July 2025 (5.4 days) both trace to RC-09. In AI-specific context: RC-09 is the root cause for DataOps FM-17 incidents \u2014 when the RAG corpus is stale or the embedding refresh failed.
Theme 7: AI / Model and Process (2%)
RC-13 Model / AI Component (243): the root cause for LLMOps FM-17 incidents \u2014 Anthropic's repeat incidents on specific Claude model versions. RC-16 Operational Coordination (114): coordination failure, missed handoffs. RC-17 Operational Action / Operator Error (new v0.9): the action itself was wrong \u2014 wrong target, wrong scope, wrong moment. GitLab's 2017 rm -rf wrong host is the human-actor canonical case. Replit's database delete during code freeze in 2025 is the AI agent equivalent.
What the Distribution Tells You
- Code + config (26%) are your highest-automation-value targets
- External dependencies (21%) call for graceful degradation architecture, not removal of dependencies
- Data pipelines (18%) are chronically under-monitored \u2014 most teams have excellent app observability and weak data-layer observability
- Auth (10%) is a quiet killer \u2014 cert expiry, token scope changes, federation dependencies
Explore the full dataset at stackgen.com/state-of-reliability. Sign up for the LinkedIn webinar.
About StackGen:
StackGen is the pioneer in Autonomous Infrastructure Platform (AIP) technology, helping enterprises transition from manual Infrastructure-as-Code (IaC) management to fully autonomous operations. Founded by infrastructure automation experts and headquartered in the San Francisco Bay Area, StackGen serves leading companies across technology, financial services, manufacturing, and entertainment industries.
