


Share This:
Every minute of downtime costs more than money—it erodes customer trust, impacts SLAs, and puts your team under pressure. What if your incident response could be as intelligent as your applications?
Platform engineers and SRE teams spend 15-25% of their time on incident response and remediation. That's nearly a quarter of their work week dedicated to putting out fires instead of building the future. Even worse, when incidents strike, engineers scramble to gather context from disparate data sources—APM tools, logs, Kubernetes metrics, cloud dashboards, and tribal knowledge scattered across runbooks and chat histories.
The result? Up to 30 minutes just to gather context, and hours or even days to fully resolve incidents. Meanwhile, your customers are waiting, your SLAs are at risk, and your team is burning out. The impact can be particularly strong for teams who respond to incidents on call; on call work is associated with less calm, a worsened mood, and lower energy and being under heavy stress shortens life expectancy by 2.8 years.
The Hidden Costs of Traditional Incident Response
Modern infrastructure incidents aren't just technical problems—they're complex puzzles that require connecting dots across multiple systems, data sources, and domain expertise. Consider what happens when your application starts throwing 500 errors at 2 AM:
- Detection: Your monitoring alerts wake up the on-call engineer
- Context Gathering: Scrambling through logs, metrics, topology maps, and previous incidents
- Recovery: Implementing quick fixes like traffic routing or rollbacks
- Root Cause Analysis: Deep diving to understand the fundamental cause
- Remediation: Permanent fixes that restore normal operations
Each step traditionally requires manual effort, domain expertise, and time—precious resources that become scarce during high-pressure situations.
Check out walkthrough of StackHealer by Aaron Yang, AI Product Manager.
Enter StackHealer: Your AI-Powered Incident Response AI Agent

StackHealer represents a fundamental shift from reactive incident management to proactive, AI-driven remediation. Unlike traditional incident management tools that focus on tracking and notifications, StackHealer focuses on intelligent remediation.
Infrastructure-Aware Intelligence

StackHealer ingests and understands your complete infrastructure context:
- Structured Data: Cloud topology, Kubernetes configurations, Terraform state, observability metrics, logs, and traces
- Semantic Context: Runbooks, Google Drive documents, chat histories, tickets, design docs, incidents, and external knowledge sources
This comprehensive knowledge layer enables StackHealer to understand not just what's happening, but why it's happening and how to fix it safely.
Automated, Real-Time Recovery: From Alert to Resolution in Under 5 Minutes
StackHealer doesn't just detect incidents—it autonomously resolves them before they impact your business. Through intelligent automated runbooks and event-driven triggers, StackHealer achieves Mean Time to Recovery (MTTR) of under 5 minutes compared to industry averages of 30+ minutes.
Our governance-aware remediation engine ensures every automated action complies with your security policies and infrastructure state, while real-time drift detection continuously monitors your infrastructure and automatically triggers corrective actions based on event signals.

This autonomous approach transforms your infrastructure into a self-healing system that maintains uptime without human intervention. The result is dramatic operational improvement: incident frequency reduction to fewer than 15 per month, increased deployment frequency, and the ability for your engineering teams to focus on innovation rather than firefighting. With one-click rollback capabilities and comprehensive audit trails, you maintain full control and visibility while your infrastructure heals itself.
Natural Language Incident Exploration
StackHealer transforms incident response from a frantic scramble into an intelligent conversation. While traditional incident management tools treat outages as isolated events requiring manual investigation across disparate data sources, StackHealer’s infrastructure-aware AI instantly correlates incidents with your actual cloud topology, codebase, logs, and APM data—understanding the critical gap between what your infrastructure should be versus what it actually is.
While alternatives force engineers to spend up to 30 minutes gathering context from multiple dashboards, StackHealer's conversational interface delivers that context in seconds, letting you focus on what matters most: getting your business back up and running as fast as possible.
Let’s explore an incident example: “Why is traffic still going to Container B if it’s throwing errors? And what are our options for fixing this?”

StackHealer's Proactive Knowledge Management
Beyond incident response, StackHealer continuously monitors your CI/CD pipelines through webhook integrations to analyze every infrastructure change and deployment in real-time. When new code is deployed, StackHealer performs intelligent diff analysis to identify new dependencies, feature flags, configuration changes, or potential failure modes that could impact operations.
By cross-referencing these changes against your existing runbooks and operational documentation, StackHealer proactively identifies knowledge gaps and automatically generates update requests through StackScribe.

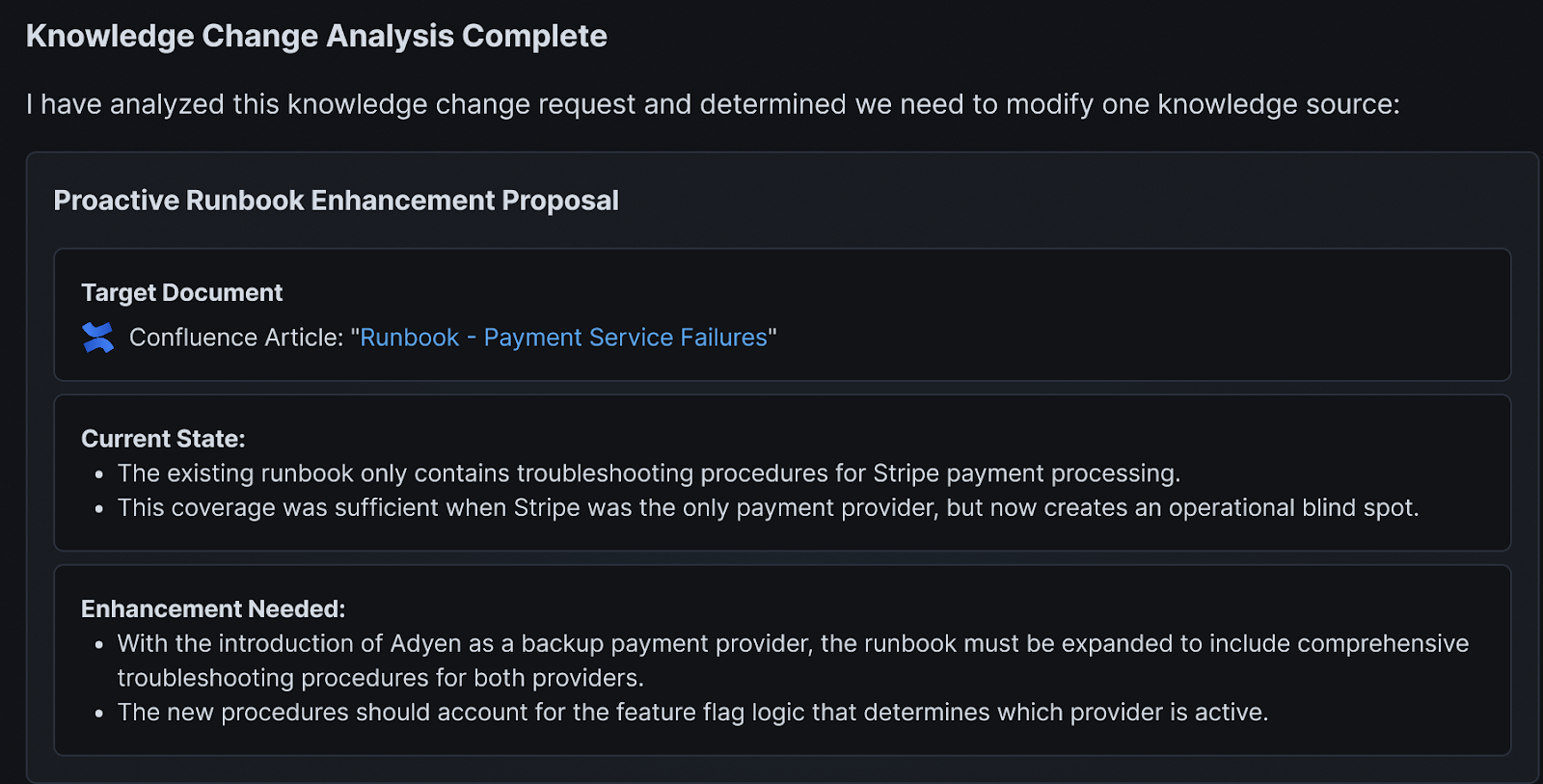
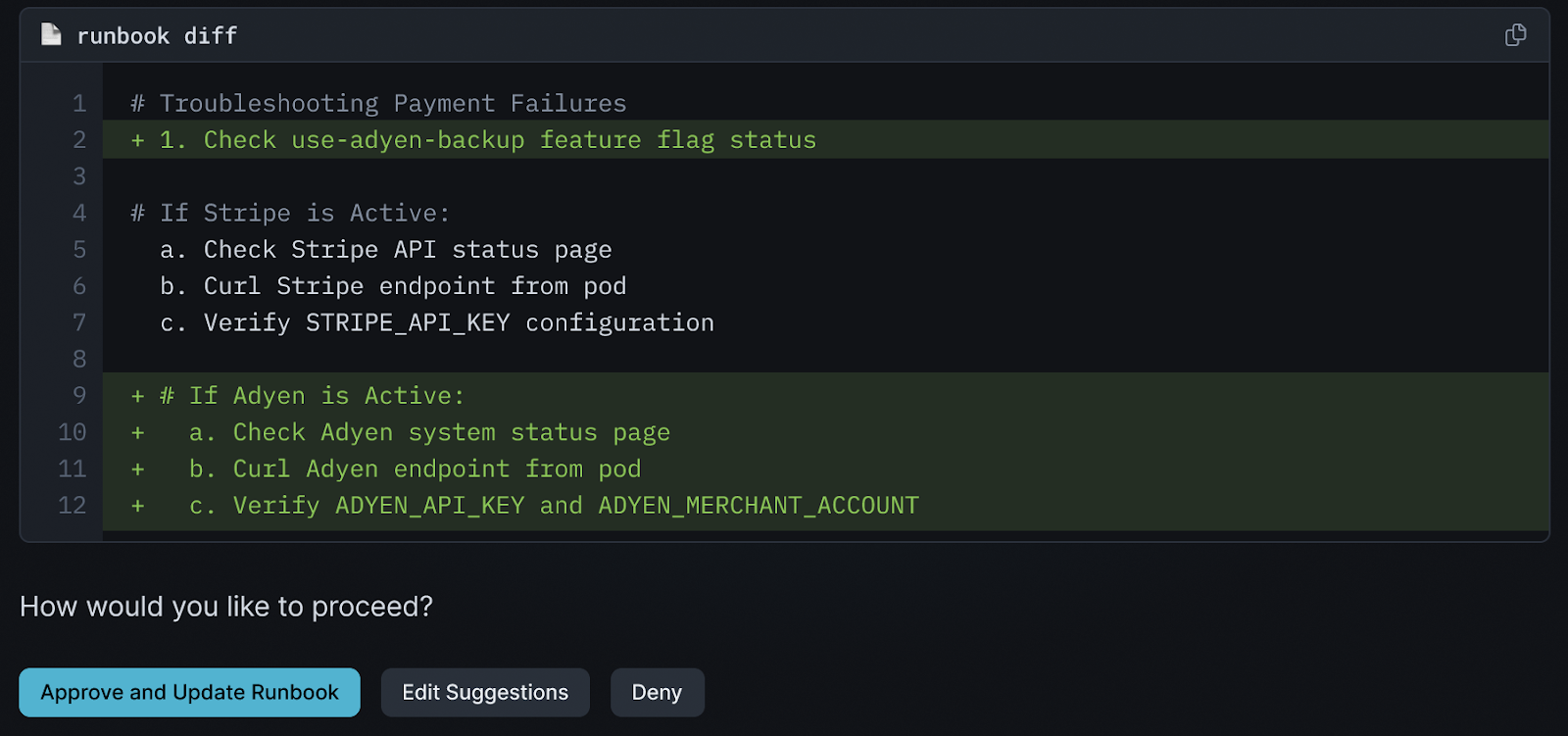
This ensures your enterprise operational knowledge stays synchronized with your rapidly evolving infrastructure, preventing the common problem of outdated runbooks during critical incidents and maintaining the accuracy of your institutional memory as your systems grow more complex.

The Four Pillars of Trust
Enterprise incident response demands more than just AI capability—it requires trust. StackHealer is built on four foundational pillars:
1. Execution Control
- Fine-grained role-based access control (RBAC)
- Explicit human approval workflows
- Whitelisted actions with least privilege enforcement
2. Data Security & Privacy
- Session data never used for model training
- Data sovereignty compliance
- Automatic PII redaction
3. AI Decision Reliability
- Full explainability of AI recommendations
- Deterministic behavior patterns
- "Read-only" mode for exploration without changes
4. Compliance & Audit
- Policy-aware remediation suggestions
- Complete audit trail integration
- Change management system integration
To learn more about our approach to trust with AI agents, check out my recent PlatformCon talk on building trusted AI agents for platform teams here.
Real-World Impact: From Hours to Minutes
StackHealer dramatically accelerates the mean time to recovery through accelerated recognition, root cause and remediation actions relative to traditional processes.
The transformation and time savings that StackHealer enables represent a fundamental shift in how teams approach the incident remediation lifecycle:
Before & After Incident Remediation Lifecycle
| Stage | Before Stackhealer | After StackHealer |
1. Detection |
Manual detection by users or basic alerts; chaotic and unstructured process taking 5-15 minutes |
Automated alert ingestion from PagerDuty, APM tools, and monitoring systems completed in 1-2 minutes (85% faster) |
2. Context Gathering |
Manually scramble across disparate data sources (APM, logs, K8s, cloud metrics, runbooks, tribal knowledge) requiring 30 minutes of frantic information gathering |
AI-powered context retrieval from unified knowledge layer with infrastructure topology awareness delivered in 2-3 minutes (90% faster) |
3. Initial Triage |
Manual analysis and correlation of symptoms across multiple dashboards taking 15-20 minutes of detective work |
Automated root cause analysis with conversational AI summary and infrastructure correlation com |
4. Recovery Actions |
Manual traffic routing, rollbacks, or infrastructure changes through ClickOps requiring 20-45 minutes of high-stress execution |
Governance-aware automated recovery recommendations with one-click execution taking 5-10 minutes (70-80% faster) |
5. Root Cause Analysis |
Manual investigation through logs, code diffs, and infrastructure changes consuming 1-4 hours of deep investigation |
AI-powered RCA with code diff analysis, deployment correlation, and infrastructure state comparison delivered in 10-15 minutes (85-95% faster) |
6. Permanent Remediation |
Manual infrastructure fixes, code changes, and policy updates requiring 2-8 hours of careful implementation |
Automated remediation suggestions with compliance checks and infrastructure-as-code integration completed in 30-60 minutes (75-90% faster) |
7. Knowledge Capture |
Manual post-mortem creation and runbook updates taking 1-3 hours (often skipped due to time constraints) |
Automated learning suggestions to StackScribe for runbook and policy updates processed in 10-15 minutes (90-95% faster) |
The Journey to SRE Maturity
StackHealer recognizes that organizations exist at different levels of SRE maturity:
Level 1 (Reactive): Manual incident response, limited automation
Level 2 (Defined): Structured processes, partial automation
Level 3 (Optimized): Fully automated, proactive incident management
StackHealer is designed to accelerate your journey from Level 1 to Level 3, with particular focus on organizations early in their SRE maturity journey where the impact is most significant.

The Future of Incident Response is Here
StackHealer represents the convergence of infrastructure automation, AI intelligence, and SRE best practices.
Want to learn more about how StackHealer can transform your incident response?
Schedule a demo to explore how AI-powered remediation can reduce your MTTR and improve your team's quality of life.
For AWS users, StackHealer is also available via the new AWS AI agent marketplace.
Join our Design Partner Program, where you can not only access early AI agents - but also actively participate in defining the Autonomous Infrastructure Platform (AIP) space alongside StackGen's product & engineering leadership team.
