


Share This:
You ship a feature. It works. A week later, someone asks why it's not in staging yet, and you realize it's behind an infrastructure request that's still in review. The ticket isn't urgent enough to escalate. It's also not small enough to ignore. So it waits.
That's what a developer productivity problem feels like at 50 engineers. Not a crisis. A tax. Paid slowly, every day, by every person on the team, and almost invisible to leadership because the work eventually ships.
The State of Developer Experience report puts numbers on it: developers lose an entire day each week to inefficiencies, work that could be automated, optimized, or eliminated. The friction lives in the handoffs, not the work itself. And the infrastructure layer, the one that was built for 20 engineers, is almost always where those handoffs pile up.
Below are the four bottlenecks causing this, and what fixes them.
The Four Bottlenecks That Cause the Stall
1. Infrastructure Provisioning Delays
At small team sizes, blockers are obvious and fast to clear. At 50+, infrastructure provisioning becomes a coordinated operational process.
- Need a staging environment? Ticket to the platform team.
- Need a new IAM role? Another ticket.
- Need an infrastructure configuration change? Another queue, another 24 to 48 hours gone from your sprint.
In most enterprises, those requests move through ServiceNow/Jira before anyone touches infrastructure. That's how changes stay tracked, approved, and auditable. The gap is in what happens between submission and fulfillment.
What starts as a few hours of implementation time becomes days of elapsed time before the infrastructure is ready for use. You keep moving where you can, but the sprint depends on environments and permissions arriving on schedule.
Leadership misses it because the requests eventually get fulfilled. Work ships. The delay tax is invisible in the output. And the platform team, the one trying to help, ends up with a reputation as a bottleneck instead of an enabler.
Faros AI's engineering bottlenecks research puts it plainly: tickets being "almost ready" and PRs "just waiting on review" are how bottlenecks hide.
Data from StackGen customer environments shows that developers wait 3+ days on average for manual infrastructure approvals. These delays compound as teams scale, increasing delivery friction and placing additional burden on platform and security teams.
2. Environment Sprawl and Setup Time
Provisioning a dev or staging environment should take minutes. For teams past 50 engineers, it typically takes hours or days.
As teams scale, environments accumulate instead of consolidating. The result:
- Fragmented setups held together by tribal knowledge
- Inconsistent configs across services and teams
- Documentation that was accurate six months ago
- Flaky environments that require multiple build retries just to confirm a real failure
New engineers pay this tax the hardest. Every hire spends days figuring out how this environment works, why this CI pipeline behaves differently, and where this service's config actually lives. That learning cost repeats with every onboarding, every context switch, every cross-team contribution.
%20(1).png?width=1200&height=628&name=2.%20The%20Four%20Bottlenecks%20That%20Cause%20the%20Stall%20(1)%20(1).png)
3. Cognitive Overload
At 20 engineers, most people hold a reasonably complete model of how the system works. At 50+, nobody does. The system has outgrown any individual's ability to reason about it.
The symptoms are recognizable:
- PR reviews slow down as reviewers navigate unfamiliar code
- Bugs cluster in areas with ambiguous ownership
- Engineers avoid touching services they don't own, even when they're the right person
- Senior engineers spend hours a week answering questions that should be self-serve
Engineering benchmarks show that when PR pickup time exceeds 24 hours, re-engagement adds significant rework. The code is no longer fresh. Context has to be rebuilt from scratch.
A significant chunk of that overhead, especially at scaling teams, comes from infrastructure complexity. Before you write a line of product code on a new service, you're already navigating cloud provisioning, security policies, and networking config, none of which is your actual job.
4. Compliance Friction Hidden Inside Every Infrastructure Change
Past a certain headcount, SOC 2, ISO 27001, and policy-as-code mandates mean every infrastructure change has to clear a compliance review. In manual workflows, that's another queue, and one with unpredictable timing.
The pattern is predictable: when compliance review is slow, teams stop initiating infrastructure changes. Workarounds accumulate. Configs go stale. Drift builds quietly until an auditor asks who approved an infrastructure change six months ago, and nobody can prove it. The process designed to reduce risk ends up concentrating it.
Most likely to feel this: Fast-growing organizations that have recently completed SOC 2 audits, teams scaling beyond a compliance-naive IaC setup, and platform teams spending more time on policy reviews than on platform work. This is especially true in regulated industries such as financial services, where teams need to build new services, including agentic AI systems, while meeting strict audit, governance, and compliance requirements.
Why the Standard Fixes Make Things Worse
When productivity stalls, three responses tend to dominate. All three can actively compound the problem:
The Fix: Accelerate the Queue
These four bottlenecks share a root cause: infrastructure workflows that require a human in the loop for every request. The platform team isn't slow. The model is.
The organizations that break this pattern keep the ticket but remove the manual fulfillment chain behind it. Platform engineers define what's allowed: compliant blueprints, approved configurations, policy rules that run automatically. Aiden handles the rest.
If provisioning is taking longer than it should, these four questions will tell you where:
- How long does it take a developer to get a working environment for a new service?
- How many tickets does the platform team have open right now, and how old are the oldest ones?
- How much of a senior engineer's week goes to infrastructure work that isn't their product scope?
- What did your last infrastructure platform renewal cost, and what actually changed after it?
If the answers are measured in days rather than minutes, the bottleneck is structural, and hiring or process changes won't fix it.
The Before and After
Self-service infrastructure doesn't mean ungoverned access. Your platform team still defines everything:
- Which IAC configurations are approved
- Which resource types are available
- Which policies apply in which environments
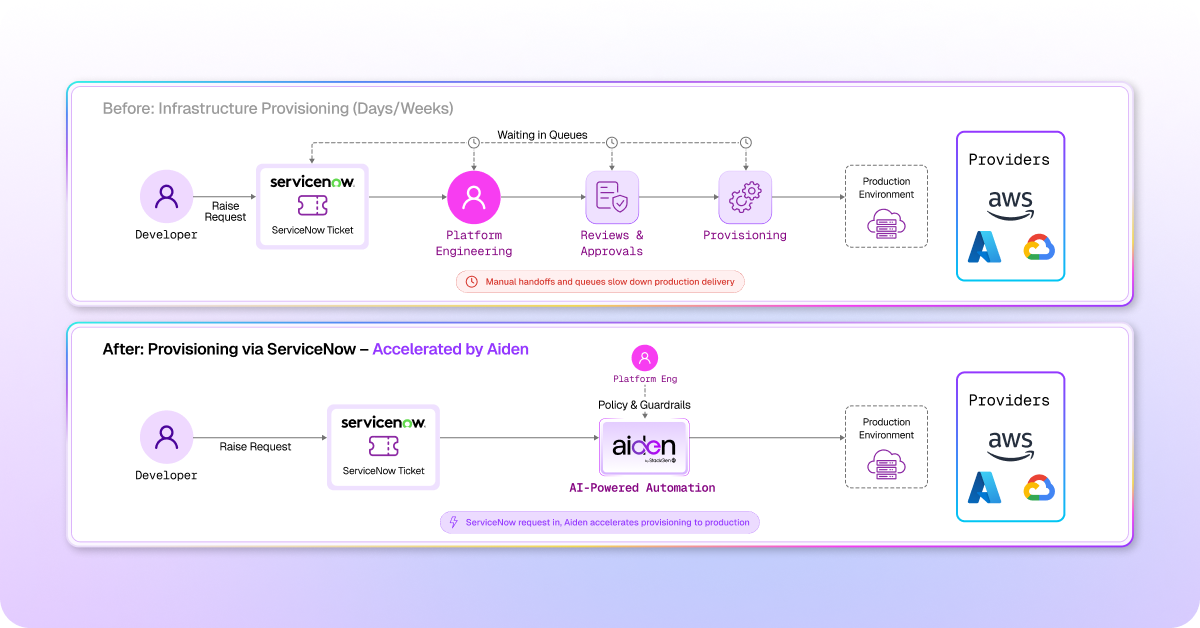
The ticket still enters through ServiceNow or Jira. Your platform team defines the guardrails once, and Aiden picks up the request from there.
You configure Aiden with a skill, a plain English instruction set that tells it what to provision and how, so when a developer types "Create infrastructure for my payment service," Aiden already knows the approved modules, the governance policies, and the project it's building for. It generates a governance-compliant environment and returns a direct link. What used to travel through three teams over three days now takes 90 seconds, with the same audit trail intact.
- The staging environment request that entered ServiceNow on Tuesday used to reach a provisioned environment by Thursday. Now it resolves in fifteen minutes.
- New engineers describe what their service needs and get back an environment that already meets your org's security and compliance requirements, committed directly to Git, ready to deploy. No tribal knowledge required.
- For engineering managers, the productivity drag becomes measurable and fixable, not just a feeling in the retro.
- For platform teams, the queue shrinks without the team growing.
Get started with Aiden today or book a demo to see how it can work in your environment.
FAQs
What is a developer productivity infrastructure bottleneck?
An infrastructure bottleneck is any point where developers have to wait on infrastructure-related tasks before they can continue building. Common examples include waiting for environment provisioning, IAM role creation, compliance review on config changes, or staging environment access. These waits rarely appear on any roadmap or velocity chart, which makes them easy for leadership to miss even as they drain significant engineering time each week.
Why does developer productivity slow down after 50 engineers?
Four structural bottlenecks compound as headcount grows: infrastructure approval queues (StackGen data shows a 3+ day average wait for manual approvals), environment sprawl that makes setup and onboarding slow and unpredictable, cognitive overload from systems that have grown faster than any individual's ability to reason about them, and compliance friction that makes developers avoid infrastructure changes entirely. The work still ships, but the time cost per task increases significantly. Hiring more engineers tends to make all four worse before it makes them better.
How do you reduce infrastructure provisioning time for engineering teams?
The most direct approach is enabling developer self-service through pre-approved infrastructure blueprints with automated compliance enforcement built in. Platform engineers define the blueprints once. Developers request and deploy from them without waiting for manual review. Tools like Aiden for Infrastructure use IaC generation and governance automation to bring provisioning time from days to under 15 minutes.
What is self-service infrastructure, and why does it matter for developer velocity?
Self-service infrastructure lets developers provision cloud resources, environments, and services without waiting for manual fulfillment after the request is filed. It matters for developer velocity because the fulfillment chain behind every infrastructure request is one of the most consistent bottlenecks for teams past 50 engineers. When provisioning is automated within pre-approved guardrails, the wait compresses from days to minutes and velocity recovers.
How do you measure whether cognitive overload is affecting your team?
Indirect signals are more reliable than surveys. The most useful ones: PR pickup time consistently over 24 hours, ratio of planned to reactive work across squads, how often senior engineers are the only answer for common questions, deployment frequency flat or declining as headcount grows, and engineers avoiding unfamiliar services even when they're the right person for a fix. Two or more of these appearing across multiple teams points to a structural cognitive load problem.
Does Aiden for Infrastructure work with existing Terraform modules and cloud setups?
Yes. Aiden generates standard Terraform or OpenTofu code and integrates with AWS, Azure, and GCP. Platform engineers bring existing modules into the appStack system rather than rebuilding. It also integrates with existing CI/CD pipelines and developer tools, including Backstage and IDE tooling via MCP.
